Longhorn Troubleshooting
This is not official documentation for AutomationSuite
If longhorn volume is not able to attach/mount to node then pod will remain in ContainerCreating or Init state and kubectl get events -n POD_NS will have below events
-monitoring-alertmanager-db]: timed out waiting for the condition
67s Warning FailedMount pod/alertmanager-rancher-monitoring-alertmanager-1 Unable to attach or mount volumes: unmounted volumes=[alertmanager-rancher-monitoring-alertmanager-db], unattached volumes=[kube-api-access-smb9d config-volume tls-assets alertmanager-rancher-monitoring-alertmanager-db secret-alertmanager-tls-secret]: timed out waiting for the condition
Longhorn volume mount may fail with following reasons,
-
Missing volume.meta file from replica directory
-
Missing metadata for img file
-
Mismatch in PVC size
-
All replicas are faulted
-
Engine image is missing
-
Corrupted meta files from replica directory
-
Pod fails to come up after node reboot due to filesystem corruption
-
TGT not able to login to volume
-
Failure in replica scheduling
1.1 Missing volume.meta file from replica directory
To identify, if volume mount is failing because of missing volume.meta file, check logs of longhorn-manager pod using below command:
kubectl logs -l app=longhorn-manager -n longhorn-system -c longhorn-manager --prefix=true --tail=-1 |grep "Failed to read info in replica directory" | grep <PV NAME>
For example, if pod is not able to mount volume pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6, then command will be:
[root@server0 ~]# kubectl logs -l app=longhorn-manager -n longhorn-system -c longhorn-manager --prefix=true --tail=-1 |grep "Failed to read info in replica directory" | grep pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6
[pod/longhorn-manager-7gdqg/longhorn-manager] time="2023-07-10T11:41:10Z" level=warning msg="pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6-r-ebc73f6b: time=\"2023-07-10T11:01:41Z\" level=error msg=\"Failed to read info in replica directory /host/datadisk/replicas/pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6-31f5410a: EOF\""
[pod/longhorn-manager-7gdqg/longhorn-manager] time="2023-07-10T11:41:10Z" level=warning msg="pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6-r-ebc73f6b: time=\"2023-07-10T11:01:42Z\" level=error msg=\"Failed to read info in replica directory /host/datadisk/replicas/pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6-31f5410a: EOF\""
1.1.1 Finding replica directory
- Once, issue is confirmed using above command, scale down workload pods which is consuming this PV.
- Post scale-down, We need to check longhorn replica directory to identify which meta file is missing.
To identify which server node is having longhorn replica directory, run below command:
kubectl get replicas.longhorn.io -n longhorn-system -l longhornvolume=<PV_NAME> -o custom-columns="NAME":.metadata.name,"STATE":.status.currentState,"NODE":.spec.nodeID,"DIRECTORY":.spec.dataDirectoryName
For our above example, it will be:
[root@server1 ~]# kubectl get replicas.longhorn.io -n longhorn-system -l longhornvolume=pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6 -o custom-columns="NAME":.metadata.name,"STATE":.status.currentState,"NODE":.spec.nodeID,"DIRECTORY":.spec.dataDirectoryName
NAME STATE NODE DIRECTORY
pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6-r-ebc73f6b running server2 pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6-31f5410a
From above output, replica directory is pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6-31f5410a and located on node server2.
Once replica node is identified, login to replica node and run ls command against replica directory under /datadisk/replicas to identify missing or empty file.
For our above example, complete directory name will be /datadisk/replicas/pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6-31f5410a and sample output of ls command will be as per below:
[root@server2 ~]# ls -l /datadisk/replicas/pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6-31f5410a
total 102368
-rw-------. 1 root root 4096 Jul 10 11:00 revision.counter
-rw-r--r--. 1 root root 2147483648 Jul 10 11:00 volume-head-006.img
-rw-r--r--. 1 root root 187 Jul 10 10:10 volume-head-006.img.meta
-rw-r--r--. 1 root root 2147483648 Jul 10 10:10 volume-snap-uipath-s-d7594081-20a7-4e85-8975-b4d07e7203df.img
-rw-r--r--. 1 root root 197 Jul 10 10:10 volume-snap-uipath-s-d7594081-20a7-4e85-8975-b4d07e7203df.img.meta
-rw-r--r--. 1 root root 0 Jul 10 11:01 volume.meta
1.1.2 Recreating volume.meta file
- From above output,
volume.metafile is empty - Use below steps to recreate
volume.metafile
Format of volume.meta file in pretty-json is as below:
{
"Size": 2147483648,
"Head": "volume-head-009.img",
"Dirty": true,
"Rebuilding": false,
"Error": "",
"Parent": "volume-snap-uipath-s-d7594081-20a7-4e85-8975-b4d07e7203df.img",
"SectorSize": 512,
"BackingFilePath": ""
}
All meta files will be in compacted format. You can use jq -c to generate compacted format.
where,
- Size is volume/PV size in Bytes. To get size of PV, run
kubectl get <PV_NAME> -o jsonpath='{.spec.capacity.storage}'and convert it into bytes. Headis volume head file name. Format of head file name isvolume-head-xxx.imgDirtyrepresent volume stateRebuildingdefines it volume requires rebuilding or notErrorrepresent any error in volumeParentrepresent the latest snapshot name. To get latest snapshot name, runls -1rth volume-snap*.img | tail -1in replica directory.SectorSizerepresent volume sector size, it should be always 512.BackingFilePathrepresent backing file for replica. It is internal to replica and should be empty.
Now, to construct volume.meta file for example volume pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6-31f5410a We need Size, Head, Parent and SectorSize information.
- To get size, run command
kubectl get <PV_NAME> -o jsonpath='{.spec.capacity.storage}'
[root@server1 ~]# kubectl get pv pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6 -o jsonpath='{.spec.capacity.storage}'
2Gi
- Since size if Gi, multiply it with 102410241024. So final size will be 2147483648.
- If PV size is in Mi, multiply it with 1024*1024.
- If it is in Ki, multiple it with 1024.
- To get
Headfile, runls volume-head-*.imgin replica directory. There will be only one head file in directory.
[root@server2 pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6-31f5410a]# ls volume-head-*.img
volume-head-006.img
- To get Parent snapshot, run
ls -1rth volume-snap*.img | tail -1in replica directory.
[root@server2 pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6-31f5410a]# ls -1rth volume-snap*.img | tail -1
volume-snap-uipath-s-d7594081-20a7-4e85-8975-b4d07e7203df.img
-
For
SectoreSize, it will be default to 512. To verify, check othervolume.metafile under/datadisk/replicadirectory.Using above information,
volume.metafile for our example volume will be,
{
"Size": 2147483648,
"Head": "volume-head-006.img",
"Dirty": false,
"Rebuilding": false,
"Error": "",
"Parent": "volume-snap-uipath-s-d7594081-20a7-4e85-8975-b4d07e7203df.img",
"SectorSize": 512,
"BackingFilePath": ""
}
Above output is pretty-json formatted. You can convert it to compact format using jq -c . command. You can write a temporary file in pretty-json format and run cat <TEMP_VOLUME_META> | jq -c . > volume.meta to convert it to compact format.
1.2 Missing metadata for img files
To identify, if volume mount is failing because of missing metadata for img files, check logs of longhorn-manager pod using below command:
kubectl logs -l app=longhorn-manager -n longhorn-system -c longhorn-manager --prefix=true --tail=-1 |grep Failed to find metadata for | grep <PV NAME>
For example, if pod is not able to mount volume pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6, then command will be:
[root@server0 pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6-d8b53e98]# kubectl logs -l app=longhorn-manager -n longhorn-system -c longhorn-manager --prefix=true --tail=-1 |grep "Failed to find metadata for" | grep pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6
[pod/longhorn-manager-7gdqg/longhorn-manager] time="2023-07-10T17:01:58Z" level=warning msg="pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6-e-b1e5c2a1: time=\"2023-07-10T17:01:53Z\" level=warning msg=\"failed to create backend with address tcp://10.42.0.72:10060: failed to open replica 10.42.0.72:10060 from remote: rpc error: code = Unknown desc = Failed to find metadata for volume-snap-uipath-s-72f4bc9f-8554-4282-b90b-ad672ab31f8b.img\""
[pod/longhorn-manager-7gdqg/longhorn-manager] time="2023-07-10T17:01:58Z" level=warning msg="pvc-f1830fec-b3b6-40e1-825f-b17930bfdad6-e-b1e5c2a1: time=\"2023-07-10T17:01:57Z\" level=warning msg=\"failed to create backend with address tcp://10.42.0.72:10060: failed to open replica 10.42.0.72:10060 from remote: rpc error: code = Unknown desc = Failed to find metadata for volume-snap-uipath-s-72f4bc9f-8554-4282-b90b-ad672ab31f8b.img\""
To find relevant replica directory for volume, follow steps from 1.1.1
1.2.1 To recreate volume-head-xxx.img.meta file
In replica directory, there will be only one volume-head-xxx.img data file and one volume-head-xxx.img.meta meta file. Name of the meta file will be same as volume-head-xxx.img with suffix .meta.
Format of volume-head-xxx.img.metafile is as below:
{
"Name": "volume-head-007.img",
"Parent": "volume-snap-1670c0ce-4cee-4bb1-addb-f6d00b03f9f9.img",
"Removed": false,
"UserCreated": false,
"Created": "2023-07-10T10:10:22Z",
"Labels": null
}
Where,
Nameis volume-head file name. It will be involume-head-xxx.imgformat. This file contains the data of volume.Parentis latest snapshot name. To get latest snapshot name, runls -1rth volume-snap*.img | tail -1in replica directory.Removeddefines if this file is removed. Forvolume-headIt will be falseUserCreateddefines if this file is created by use, not longhorn. Value of this field will be false by default.Createdrepresent creation time-stamp ofvolume-headfile. You can set it to timestamp ofvolume-headfileLabelsrepresent labels of volume-head. Default value for this will benull
Based on above information, To re-construct volume-head-xxx.img.meta file, We need Name, Parent and Created values.
- To get Name , run
ls -1 volume-head-*.imgin relevant replica directory. - To get Parent snapshot name, run
ls -1rth volume-snap*.img | tail -1 - To get Created, run
date -u -d @stat -c '%X' volume-head-*.img+"%Y-%m-%dT%H:%M:%SZ"
Using above information, volume-head-xxx.img.meta file for our example volume will be,
{
"Name": "volume-head-006.img",
"Parent": "volume-snap-uipath-s-d7594081-20a7-4e85-8975-b4d07e7203df.img",
"Removed": false,
"UserCreated": false,
"Created": "2023-07-10T15:20:08Z",
"Labels": null
}
Above output is pretty-json formatted. You can convert it to compact format using jq -c . command. You can write a temporary file in pretty-json format and run cat <TEMP_VOLUME_META> | jq -c . > volume-head-xxx.img.meta to convert it to compact format.
1.2.2 To recreate volume-snap-xxx.img.meta file
In replica directory, there will be multiple volume-snap-xxx.img data files along with its volume-snap-xxx.img.meta meta files. Meta file for relevant snapshot file will be having same name with suffix .meta.
Format of volume-snap-xxx.img.meta file is as below:
{
"Name": "volume-snap-1670c0ce-4cee-4bb1-addb-f6d00b03f9f9.img",
"Parent": "volume-snap-uipath-s-d7594081-20a7-4e85-8975-b4d07e7203df.img",
"Removed": true,
"UserCreated": false,
"Created": "2023-07-10T14:20:22Z",
"Labels": null
}
Where,
Nameis volume-snap file name. It will be involume-snap-xxx.imgformat. This file contains the data of snapshot.Parentis latest snapshot name older than the snapshot we are fixing. To get latest snapshot name older to current one , list snapshot imagesvolume-snap-*.imgin timestamp order and select the recent older snapshot before the snapshot for which we are fixing the meta file. If there are no any older snapshot then leave Parent field empty.Removeddefines if this file is removed. If Parent field is empty then set Removed as false.UserCreateddefines if this file is created by use, not longhorn. Value of this field will be true if snapshot is havingvolume-snap-uipath-xxformat else false by defaultCreatedrepresent creation time-stamp ofvolume-snap-xfile. You can set it to timestamp ofvolume-snap-xfileLabelsrepresent labels of volume-head. Default value for this will benull. If snapshot was created by recurring job , i.e uipath-snapshot, then set Labels to{"RecurringJob": "uipath-snapshot"}
Once you have all above information, you can construct volume-snap-xxx.img.meta file as below, compact it and save it.
{
"Name": "volume-snap-uipath-s-239a4ab1-7d53-4427-9ce9-fc0185fbfa77.img",
"Parent": "volume-snap-uipath-s-903643d4-f8e0-4f24-8e33-86c7c1680c3d.img",
"Removed": false,
"UserCreated": true,
"Created": "2023-07-10T14:10:04Z",
"Labels": {
"RecurringJob": "uipath-snapshot"
}
}
Above output is pretty-json formatted. You can convert it to compact format using jq -c . command. You can write a temporary file in pretty-json format and run cat <TEMP_VOLUME_META> | jq -c . > volume-snap-xxx.img.meta to convert it to compact format.
1.3 Mismatch in PVC size
If longhorn volume remains in attaching-detaching state, there might be an issue with PVC size. To confirm, if volume is not able to attach because of PVC size mismatch, run below command:
kubectl logs -n longhorn-system -l longhorn.io/instance-manager-type=engine --prefix=true --tail=-1 |grep "BUG: Backend sizes do not match" |grep <PV_NAME>
Sample output of above command will be as below:
[root@server0 ~]# kubectl logs -n longhorn-system -l longhorn.io/instance-manager-type=engine --prefix=true --tail=-1 |grep "BUG: Backend sizes do not match" |grep pvc-f322bf2f-7448-490c-9032-3d337cc5c858
[pod/instance-manager-e-18648e5c/engine-manager] [pvc-f322bf2f-7448-490c-9032-3d337cc5c858-e-9fa69db1] 2023/07/11 07:21:15 BUG: Backend sizes do not match 2147483648 != 524288000 in the engine initiation phase
In above example, pvc-f322bf2f-7448-490c-9032-3d337cc5c858 size is incorrect.
To fix this issue,
- Scale down workload pods
- Edit
volumes.longhorn.ioobject for relevant PV using commandkubectl edit volumes.longhorn.io -n longhorn-system <PV_NAME>and makespec.nodeIDfield empty(""). - Resize PVC object to correct size. To resize, run
kubectl edit pvc -n <NS> <PVC_NAME> and update spec.resources.requests.storageto correct value. - Check
volume.metafile’s content of relevant replica directory. If size is not correct, update the size involume.metafile. Please refer 1.1.1 to fetch replica directory. - Scale up workload pods.
1.4 All replicas are faulted
If longhorn replicas are in faulted state and requires manual salvage then volume may not be able to attach and remain in detach state.
To identify if volume requires manual salvage, Run below commands:
kubectl logs -l app=longhorn-manager -n longhorn-system -c longhorn-manager --prefix=true --tail=-1 |grep "set engine salvageRequested to true" | grep <PV NAME>
Sample output of above command will be as below:
2023-11-20T18:22:16.667609096+11:00 time="2023-11-20T07:22:16Z" level=info msg="All replicas are failed, set engine salvageRequested to true" accessMode=rwo controller=longhorn-volume frontend=blockdev migratable=false node=rpa-suite-dev-01.it.csiro.au owner=rpa-suite-dev-01.it.csiro.au state=detaching volume=pvc-031fd6bc-9cfe-420a-9213-da38509d733a
To fix this issue,
- Scale down workload pods
- Find replicas of relevant volume using command
kubectl get replicas.longhorn.io -n longhorn-system |grep <PV_NAME> - Edit replicas.longhorn.io object for relevant PV using command
kubectl edit replicas.longhorn.io -n longhorn-system <REPLICA_NAME>and setspec.failedatfield empty(""). - Scale up workload pods.
1.5 Engine image is missing
Longhorn uses engine image to deploy the volume. This engine image is tightly coupled with installed longhorn version, longhorn version 1.3.3 requires engine image 1.3.3 only.
Upgrading longhorn doesn’t upgrade engine image to respective version. There are few scenarios in which longhorn may upgrade the engine image, like node reboot, volume detach-attach. But this is not guaranteed as this may leaves few volume with old image.
To identify if volume is not able to attach because of this issue, run below command:
kubectl logs -l app=longhorn-manager -n longhorn-system -c longhorn-manager --prefix=true --tail=-1 |grep "is not deployed on at least one of the the replicas" | grep <PV NAME>
Sample output of above command will be as below:
2023-11-23T13:55:26.306811530Z time="2023-11-23T13:55:26Z" level=warning msg="HTTP handling error unable to attach volume pvc-8aaf3ecd-9812-46ce-9eed-b41a95a08106 to czchols5558.prg-dc.dhl.com: cannot attach volume pvc-8aaf3ecd-9812-46ce-9eed-b41a95a08106 because the engine image longhornio/longhorn-engine:v1.2.2 is not deployed on at least one of the the replicas' nodes or the node that the volume is going to attach to"
To fix this issue,
- Scale down workload pods
- Open errored volume in longhorn UI and select upgrade engine, choose latest available engine image.
- Scale up workload pods
If there are number of volumes running into this issue, you can run below script which will upgrade all the volumes to the given version longhorn_engines_upgrade.sh
Note: If there are already volumes which are not being able to attach then uncomment ENABLE BELOW RETURN block and run the script.
In case of offline installation, if old engine image doesn’t exist in docker-registry then above script or manual upgrade from UI will fail. Before upgrading to latest version, You need to seed old engine image to docker-registry.
1.6 Corrupted meta files from replica directory
Similar to section 1.2
1.7 Pod fails to come up after node reboot due to filesystem corruption
Sometimes when host gets rebooted the insights-insightslooker pod fails to come up due to volume attachment issue. When this happens the insights app gets stuck in progressing state
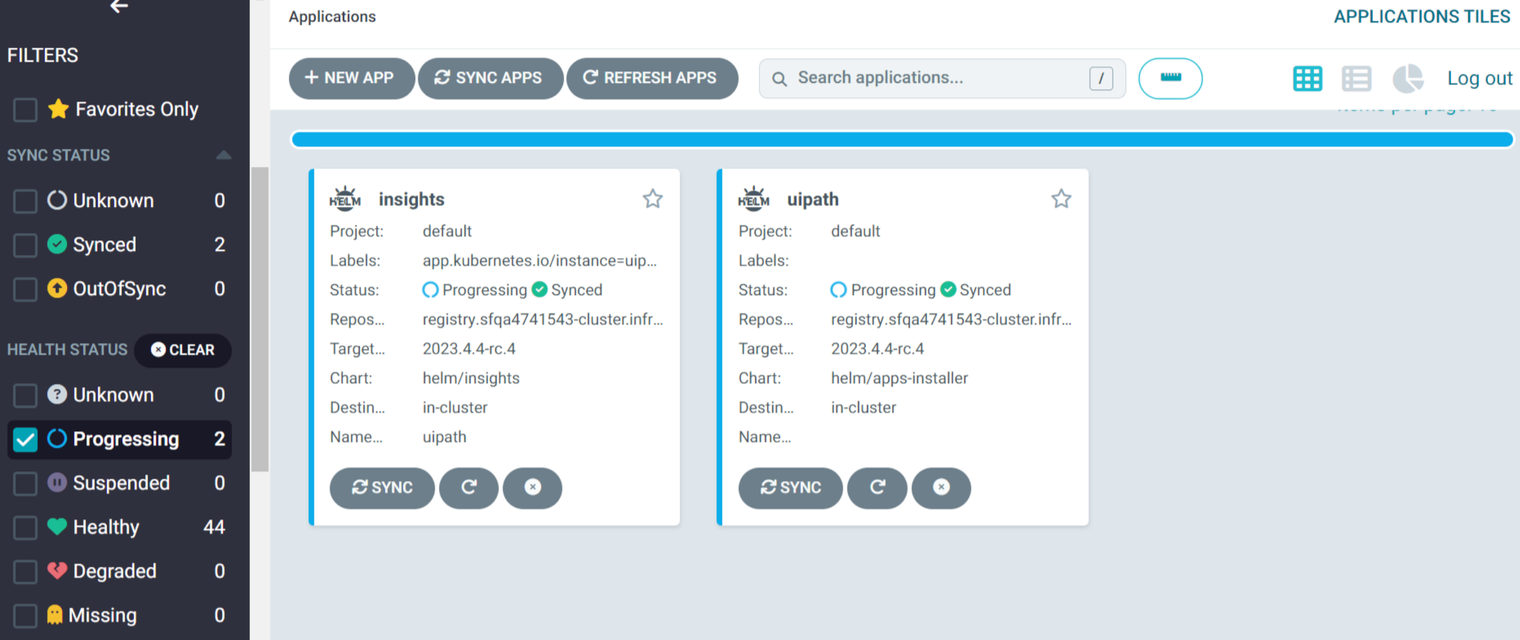
Go the insights-insightslooker pod in argocd ui, the events for the pod should show error message like below.

Solution:
- Identify the volume from the above message here its
pvc-5abe3c8f-7422-44da-9132-92be5641150a - Scale down the workload which using the errored volume. Ensure that volume is detached from the node. You can check output of
kubectl get volumes.longhorn.io -n longhorn-system |grep <PV>to verify volume is detached. - Manually attach the errored volume to any node from longhorn UI.
- Login to the node and fix the device corresponding to that volume.
fsck.ext4 /dev/longhorn/<ERRORED_VOLUME>
Example:
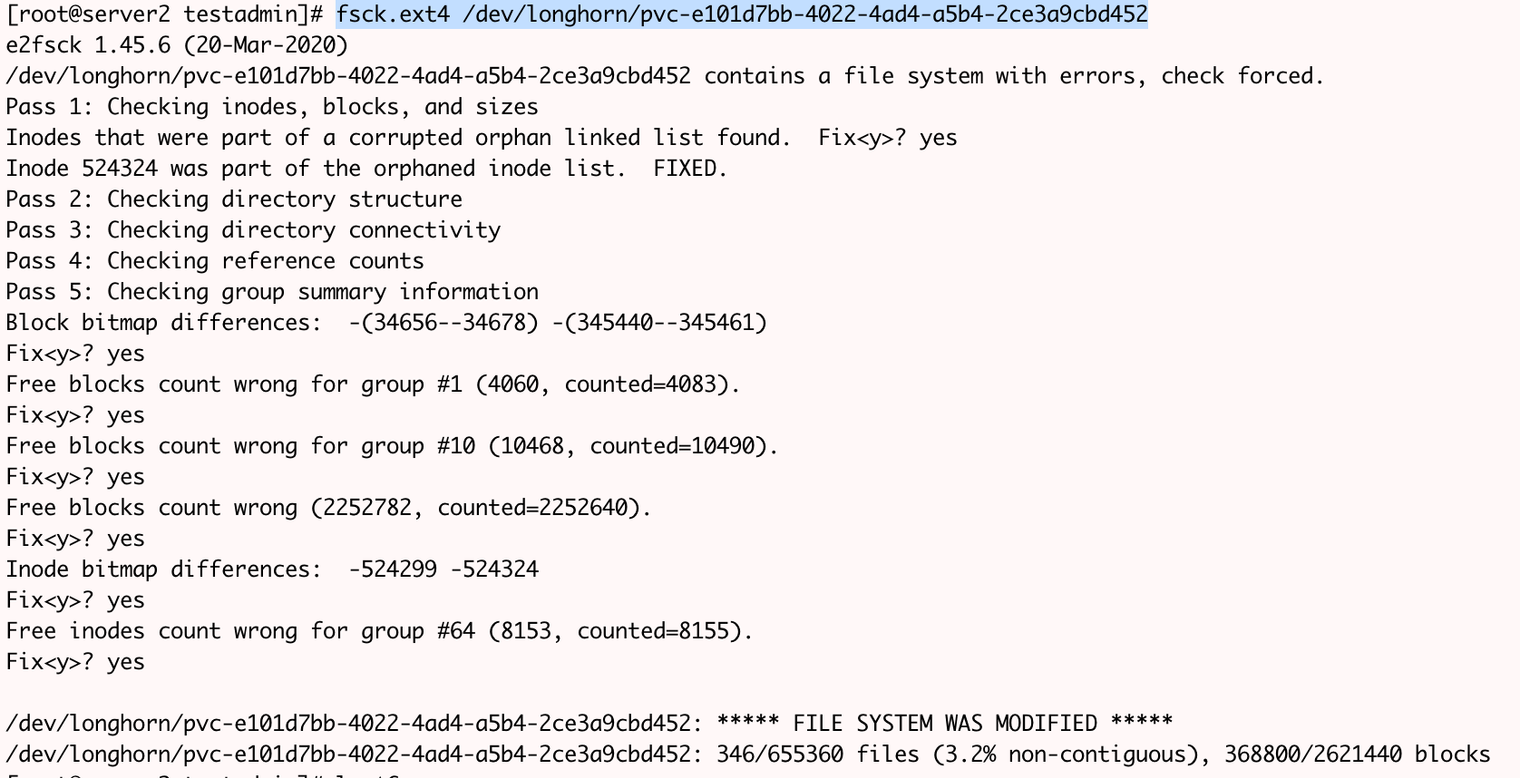
- Once errored volume is repaired, detach it from the node. This can be done from longhorn UI.
- Scale up the workload.
The pod should come up automatically and after sometime the pod becomes healthy.